| 5.1. Data Layout Problems | ||
|---|---|---|
 | Chapter 5. Memory Performance Problems and Solutions |  |
| 5.1. Data Layout Problems | ||
|---|---|---|
| | Chapter 5. Memory Performance Problems and Solutions | |
Data layout problems is a large class of related problems that originate in how the programmer or the compiler organizes the variables and objects that the program uses in memory. This is affected by choice of data structures and data types, as well as the ordering of objects within such structures.
The common property of all data layout problems is that data that is frequently used is mixed in the same cache line with data that is rarely or never used. There are many reasons why this may happen.
Bad data layout is penalized twice:
Bad data layout increases the number cache lines needed to hold the frequently used data, which increases the number of cache misses and cache line fetches.
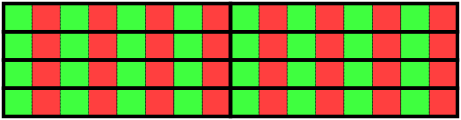
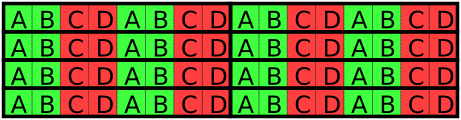
For example, assume that a part of an application frequently needs to sequentially go through a large number of 8-byte values, and that the processor uses 64-byte cache lines. If the data is optimally packed 8 of these values can be stored in each cache line, but if it is interleaved with other 8-byte values only 4 values can be stored in each cache line. See Figure 5.2, “Good Utilization” and Figure 5.3, “Poor Utilization”. With the poorly packed data twice as many lines need to be accessed when going through the values, and with the same miss ratio it causes twice as many cache misses.
Bad data layout also increases the cache miss ratio by reducing the effective cache size, that is, if data is poorly packed less useful data will fit in a cache of a certain size. This way bad data layout increases the cache miss ratio.
For example, in the example above twice as many of the frequently accessed values in the cache in the optimally packed case compared to the interleaved case.
Since bad data layout increases the number of cache line fetches it also increases the memory bandwidth requirement of the application. For applications that are limited by the available memory bandwidth this can have a serious performance penalty.
A common cause for poor data layout is structures that are only partially used. Modern programming paradigms call for people to collect related data in structures or objects. However, this is often harmful to cache performance.
Consider the following example. Here we have a structure we four
fields a, b, c
and d. All the fields may be used somewhere
in the application, but in the most performance critical loop
only a and b are
used.
struct record {
int a;
int b;
int c;
int d;
};
struct record r[SIZE];
for (int i = 0; i<SIZE; i++) {
r[i].a = r[i].b;
}
Nevertheless, the unused fields are brought into the cache from memory, doubling the number of cache line fetches and occupying half of the cache space.
If this code can be rewritten so that the rarely used fields are moved to a separate structure:
struct record_ab {
int a;
int b;
};
struct record_cd {
int c;
int d;
};
struct record_ab r_ab[SIZE];
struct record_cd r_cd[SIZE];
for (int i=0; i<SIZE; i++) {
r_ab[i].a = r_ab[i].b;
}
The performance critical loop will now only load the fields that are actually used into the cache.
This optimization should only be used when it is actually needed. Most programmers will find the modified code ugly and harder to read, and the change goes against all that is taught about programming. However, when used carefully this optimization can result in very large performance improvements.
A problem very similar to having unused fields is to use larger data types than necessary. The effect is the same. Fewer fields fit into each cache line, causing more cache line fetches and a higher cache miss ratio.
For example, if a 64-bit data type is used where a 16-bit data type would be sufficient, only a forth as many elements will fit into a cache line.
Unfortunately Freja is not able to determine if data types are larger than necessary. The generated reports will therefore not warn about this type of problem, and you have to manually check the code for it.
Many modern processors require memory accesses to be made to aligned addresses. Some processors support unaligned accesses, but the performance of aligned memory accesses are usually still better.
Most processors require natural alignment. This means that a field has to be stored at an address that is a multiple of its size, for example, a 4-byte field has to be stored at an address that is a multiple of 4 and an 8-byte field has to be stored at an address that is a multiple of 8.
Compilers are aware of this and insert padding between variables and fields to ensure that each field starts at an address with correct alignment for its particular data type. This padding consumes cache space, and this waste can often be avoided or minimized by careful ordering of structure members. Consider this example:
struct record {
char a;
int b;
char c;
};
Assume that char is a 1-byte data type and int is a 4-byte data
type. The compiler will then lay out data three bytes of padding
between fields a
and b to ensure
that b is stored at an offset that is a
multiple of 4.
If you move the field a
after b the alignment requirements of all
fields can be satisfied without an padding.
struct record {
int b;
char a;
char c;
};
You can of course count offsets into the structure yourself and assure all fields get proper alignment without any padding, but a simpler way to ensure that there is no unnecessary padding is to simply sort the fields by their alignment requirements. Start with the fields with the greatest alignment requirements and then continue with the fields in declining alignment requirement order.
If your structure is so large that it uses more than one cache line you may however want make sure that the most commonly used fields are close together, so that you avoid mixing frequently used fields and rarely used fields as described in Section 5.1.1, “Partially Used Structures”.
We have now eliminated the internal alignment padding in the structure. However, there is also an alignment requirement on the structure as a whole. Consider this example where an array of structures is created:
struct record {
int b;
char a;
char c;
};
struct record v[1000];
The structure may, for example, require 8-byte alignment. Since the structure is 6 bytes large, the compiler has to insert 2 bytes of padding between each structure in the array to ensure alignment.
External alignment like this is harder to avoid than internal alignment. One way may be to break out less frequently used fields as described in Section 5.1.1, “Partially Used Structures”.
If the processor does not strictly require alignment but simply prefers it for better performance, like, for example, x86 processors, the compiler may provide pragmas that you can use to tell it to not insert any padding. The performance increase from reduced cache misses may outweigh the cost of the unaligned memory accesses.
Using unaligned structures like that may however cause other problems, for example, shared libraries compiled with such pragmas may be incompatible with code compiled with other compilers.
Many implementations of standard memory allocators reserve extra housekeeping data adjacent to each piece of allocated memory. This data is typically only used when allocating and deallocating the areas, and is unused for the larger part of the application execution.
If many small memory allocations are done by the application a significant part of the cache lines can be occupied by this housekeeping data. Consider an application allocating 32-byte structures with a memory allocator that allocates 16 bytes of data for housekeeping:
This problem can be avoided by avoiding allocating many individual objects. If you need to allocate 1000 objects, allocate an array with 1000 objects instead of allocating 1000 individual objects.
You may even want to consider implementing your own custom memory management. It could allocate a sizable chunk of memory, and then hand out memory regions within this block. This way the overhead is kept at a minimum.
There are also alternative memory allocation packages available that allocate their housekeeping data in a different memory region than the allocated memory to avoid this kind of problem.
Dynamic memory allocation may also spread allocated memory regions over the heap causing random access patterns, see Section 5.2.2, “Random Access Pattern”.
| |  | |
| Chapter 5. Memory Performance Problems and Solutions |  | 5.2. Data Access Pattern Problems |